seq2seq
context vector가 하나임
방대한 인포매이션에 대해서 한계가 존재함
attention model = encoder decoder model
인코더 파트
step 1 I love you 를 받기
최종적인 h3가 나옴
이는 seq2seq에서 전통적인 context vector를 의미함
step 2 fully connected함
인코더의 rnn셀에서 나온 h1, h2, h3와 최종적인 h3를 넣음
현재는 디코더에서 나온 값이 없기 때문에 이전값인 h3를 넣은 것임
step 3 각 인코더에 있는 state의 score
s1, s2, s3
step 4 softmax -> 확률값 나옴
이는 attention weight 라고 함
얼마만큼 포커스 할 것인지? 알 수 있음
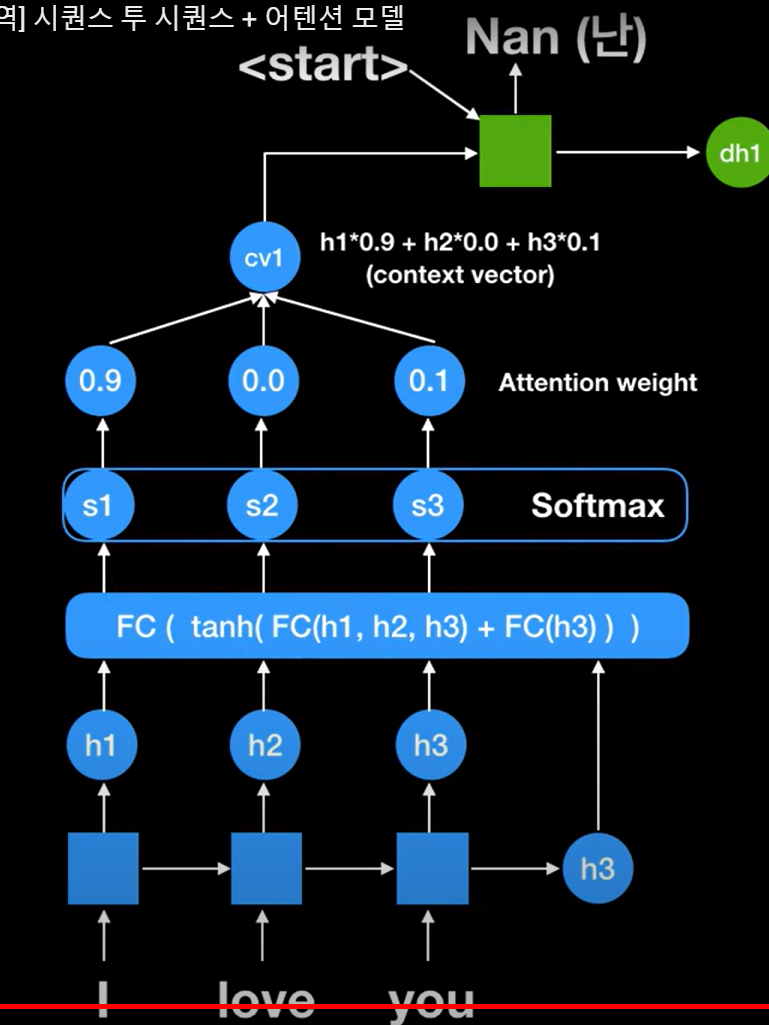
I 90%, love 0%, you 10% 포커스!
step 5 각각의 h와 attention weight 곱한 후 더함
이는 context vector 라고 함

start 시그널 넣기
step 1 cv1 을 디코더의 첫번째 rnn 셀에 넣음
이는 start 시그널이라 함
-> 첫번째 output인 Nan 나옴
step 2 cv2를 넣음
-> nul (널) 나옴
cv2는 fully connected할 때 이전값이 dh1으로 들어감
또한 cv2 계산시 h1, h2, h3값은 항상 쓰임
어떤 값을 포커스 할것인지 정하기 때문임

step 3 cv3를 넣음
-> saranghey(사랑해) 나옴
cv3는 fully connected할 때 이전값이 dh2으로 들어감

end 시그널이 나올때까지 진행

seq2seq 비교시 dynamic context vector 만듦
teacher force
만약 wrong prediction 했으면??

pred 넣은 것이 아니라 정답을 인풋으로 넣어줌

-------
transformer
rnn을 사용하지 않았기 때문에 빠름!
-> 병렬화 = parallelization
-> 한 방 에 처 리
how? psitional encoding 사용
sin cosin 사용함
-1 ~1 사이의 값
residual
encoder layer
rnn을 attention에서 성공적으로 제거함
논문 : attention is all we need
encoder decoder를
고정된 크기의 문맥 벡터를 사용하지 않음