RNN 시간을 다루는 딥러닝
시점별로 들어오는 데이터를 활용해 일어날 일을 예측함
언어모델인 챗 지피티
언어! : 어떤 단어가 올지 예측하면서 말을 구성하는 것임
중고차량의 가격 예측
시계열 데이터
: 시간의 흐름에 따라 관찰된 값을 가지는 데이터
- 변화하는 추세
- 주기
- 계절성
- 불규칙성
시계열
- 연속형(Continuous) : 자료가 연속적으로 생성
- 이산형(;범주형, Discrete) : 이산적인 시점에서 자료가 생성 - !!언어!!
Auto regression?
자기 자신을 사용하기 때문에 Auto
미래의 값이 과거의 값이 얼마만큼의 영향을 미치는지?

AR, ARMA, ARIMA 모델
- 통계적 관점을 가지고 예측
- 한계
회귀분석은 4가지 가정을 만족시켜야 사용할 수 있음
- 선형성
- 독립성
- 등분산성
- 정규성
-> 이를 만족하지 못하면 적용하기 어려움, 그래서 딥러닝 적용!
RNN을 통해 Series Data를 사용
Recurrent 하다고 함
예시)
report, work : n, v 모두 사용 가능
의미만 따지는 것은 오류가 많음!
그래서 이전에 사용한 단어가 무엇인지, 어떤 문장 구조인지 알아야 함
-> 순차적으로 품사 예측 가능, 문장 구조 파악 가능

예측) 주식 종가
1~5일 데이터를 이용해서 6일 데이터를 예측함
여러 형태의 예측을 가능하게 함
여러개 인풋 -> 여러개 아웃풋 뽑음
구조가 많음
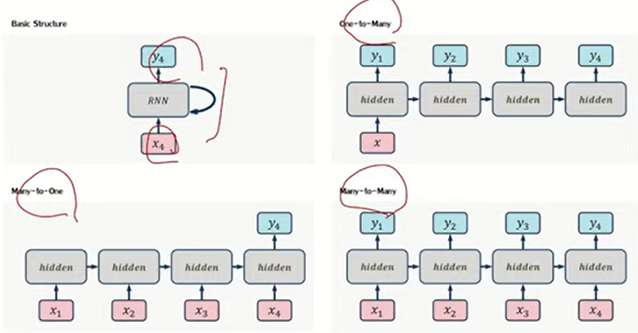
Basic Structure
One-to-Many
Many-to-One
Many-to-Many
퍼셉트론 복습
x input -> w곱해서 h를 뽑아내고 -> f를 뽑아냄
w합, b더함 -> activation function곱함
x를 받고 w 곱함 -> h나오면 w 곱함 -> b 더하고 -> 새로운 ht를 뽑아냄
명사, 접속사, 대명사 등등이라면 SoftMax 통과하면 각 어떤 품사일지에 대한 예측값이 나옴
이 예측값을 다 더하면 1임
E를 사용할 수 있음 LossFunction
예측값과 실제값 예측 -> backpro (역전파)를 통해 하이퍼파라미터 조정 가능
Gradient Vanishing 문제 발생
RNN은 어떻게 발생??
ex) 긴 문장을 학습
단일한 퍼셉드론 구성
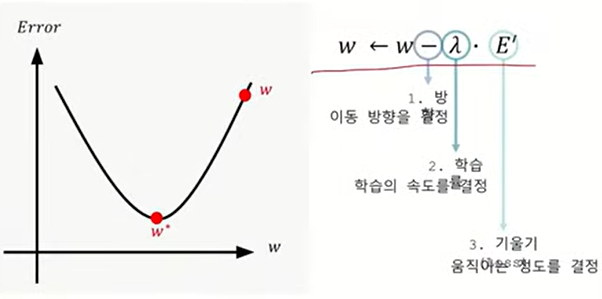
구하고 싶은 w가 있는데
즉 , 오래된 것에 대해서 잘 기억하지 못함
문장의 길이가 길면 -> 처음 나온 단어를 잃어버려 문장 전체를 이해하지 못함
ht-1을 사용함
w를 업데이트를 많이 해야 함 - 기시감!...
역전파로
미분값 계속 곱해나감 -> 그러면서 chain으로 업데이트 함
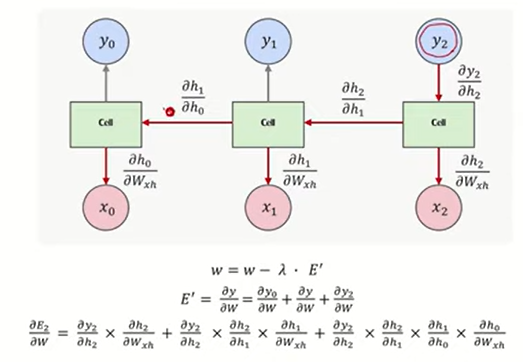
1에 가깝더라도 0에 가까워짐 -> 그래서 그래디언트가 0에 가까워짐
LSTM
시각마다 전파되는 벡터의 메모리 컴포넌트와 히든 컴포넌트로 쪼개어 Long-term
즉, 길게 관리하고 싶은 것과 짧게 관리하고 싶은 것을 분리해서 관리함
Long Term
Shot Term
기존에 ht만 넘겨줬는데 이제는 ct와 ht를 같이 넘겨줌
이전에 넘어왔던 값들 중에서 얼마나 반영시킬지 정할 수 있음
0. Gate
오래전의 내용을 기억하기 위해 메모리에 넣어 계속 보관함
but 용량의 한계가 있어서 그 메모리 내 정보를 삭제해야 하는 경우가 있음
1. Forget Gate
불필요한 정보를 시그모이드 함수를 이용해 지움
시그모이드 함수 통과 -> 0과 1사이의 값을 뽑아냄 예를 들어서 0.2가 나왔음!
이전 받아온 값에 시그모이드를 통과한 값을 곱함
-> 0.2만큼만 반영함

2. Input gate
탄젠트 계산하고 넘어온 값을 더함 -> 중요한 정보를 더 담음
3. Output gate
시그모이드 통과해서 넘어온 것 + Input gate 통과해서 탄젠트 계산한 것 곱함
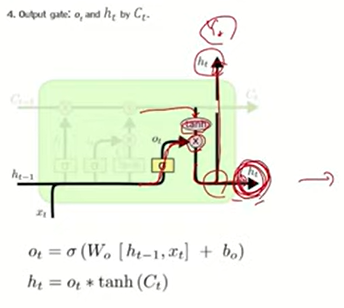
정리 : 0과 1사이의 값을 곱해서 잊어버려야 할 값을 잊어버리게 만들고
탄젠트 곱해서 단순히 더함
한계
복잡한 내부 구조
장기 의존성
높은 계산 비용 : 대규모 데이터 처리하는 데 시간 걸림
불균형 데이터 성능 낮음
GRU
LSTM의 간단한 버전
Gated recurrent unit
3개의 게이트를 이용해 정보의 흐름 관리 -> but 2개를 이용해 같은 일 수행함
LSTM보다 GRU를 사용해 모델 사이즈 줄이고 성능 유지하고자 함
Bidirectional RNN
글 속에 단어는 서로 앞뒤로 관계를 가지고 있음
-> 왼쪽에서 오른쪽, 오른쪽에서 왼쪽으로 양방향으로 sequence를 모델링하면 그 성능이 더욱 좋음
이를 합친 것을 의미함
출력이 어더한 형태로 만들어지는지 알 수 있음
---
자연어처리
사람과 컴퓨터가 서로 자연어를 사용해 상호작용할 수 있는 것
이는 사람의 언어를 기계가 이해할 수 있도록 만드는 것
컴퓨터비전과 마찬가지로 자연어를 이해하고 사용할 때 자동화를 함
ex) 기계변역, 정보 검색, 대화 모델, 감정분석
감정분석 : 텍스트를 긍정, 중립, 부정으로 분리
RNN 연속적인 데이터인 S
자연어, 즉 텍스트의 글은 단어들의 시퀀스로 볼 수 있기에 자연어처리에 있어서 RNN 사용
RNN
매 시각마다 두 개의 입력 받음
- 그 시각에 발견되는 입력 x_i
- 이전 시각의 출력 s_i-1
두 개의 입력을 연산을 통해 해당 시각에서의 출력을 함
-> 이출력을 다시 다음 시각의 입력으로 동작하게 함
RNN을 학십시킬 때
매 시각마다 나오는 출력과 실제 출력이 되어져야 하는 데이터의 차이를 구해서 학습
Linear regression, Logistic regressio, CNN등 다양한 모델과 유사함

RNN Uses
2가지 방법이 있음
1. 대화모델 or machine translation, 기계번역
단어 또는 문장을 생성하고 싶을 때 사용함
2. Encoder
모든 단어에 대해서 전부 살펴본 후 최종적으로 고정 크기의 벡터를 만듦
text에 대해서 어더한 하나의 고정된 크기의 벡터를 출력물로 만들고 싶을 때 사용

text classifier
주어진 텍스트를 받아서 RNN으로 어떤 특정 크기를 가지는 벡터인 Encoder의 형태를 사용
이를 fully connected network를 통과시켜 최종적으로 class 추록하는 방식으로 만듦

'Machine Learning & Deep Learning > Kmooc' 카테고리의 다른 글
| 비전공자를 위한 AI 딥러닝 Week 10. CNN (0) | 2023.08.10 |
|---|---|
| 비전공자를 위한 AI 딥러닝 Week. 7 DNN (0) | 2023.08.10 |
| 비전공자를 위한 AI 딥러닝 Week. 3 Colab과 TensorFlow (0) | 2023.08.03 |
| 비전공자를 위한 AI 딥러닝 Week. 2 NN과 Perceptron (0) | 2023.07.27 |
| 비전공자를 위한 AI 딥러닝 Week. 1 딥러닝이란? (0) | 2023.07.27 |