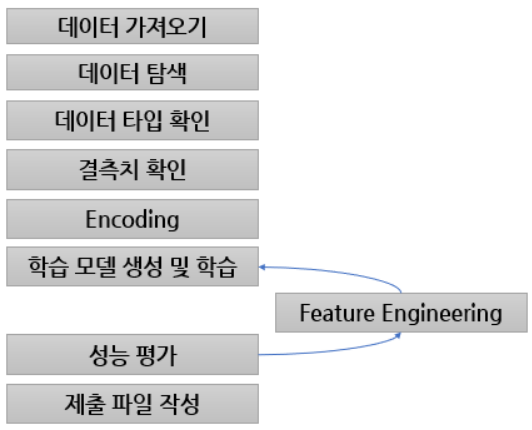
2유형 과정 주의사항 객체 출력 안 됨 -> print()사용 ! 코랩환경 아님 -> 코드를 길게 쭉 입력해야 함 ! 전처리 파트 문제지 요구사항ㅇㅔ 제시된 칼럼의 타입이 파일에서 읽어온 데이터와 동일한가? 숫자가 아닌 문자 포함 -> object로 표기되며 해당 문자를 찾아서 없애기 1. astype('int') or float로 변환 시도 -> 오류시 2. series.replace(regex=True) or Series.str.replace()사용 3. 다시 astype() 변환 날짜/시간 1. pd.to_datetime(Series, forma='%Y%m%d') 사용 1.1 일반적으로 astype('datetime64')로 가능 # 새로운 칼럼으로 추가하는 것이 좋음 # 원본으로 돌리지 않아도 됨..